Tareas de mantenimiento de PostgreSQL
.jpeg?access_token=d745456a-84fb-4b70-9a22-9cb400c14b31)
Odoo trabaja, y seguirá trabajando por varios años más, con PostgreSQL. Que es una excelente base de datos open-source. La verdad es que en mi experiencia, requiere poco mantenimiento. Sin embargo, a medida que pasa el tiempo y si la base de datos crece, requiere mantenimiento. No mucho, pero si mantenimiento (sobre todo para acelerar la ejecución de ciertas consultas en Odoo). No es necesario ser un DBA, pero si manejar algunos aspectos básicos que vamos a cubrir a continuación (no cubrimos el backup debido a que hablaremos de eso en otro post).
Que es el sequential scan?
El sequential scan sucede cuando una base de datos tiene que leer todos los registros de una tabla para responder a una consulta. Puede ser caro o no hacerlo. Por ejemplo si la tabla tiene pocos registros, puede ser inofensivo. Si la tabla tiene millones de registros, pasa a ser dañino para la performance de la base de datos. Para evitar los sequential scans se crean los índices que junto con el optimizador de la base de datos, eligen el plan de ejecución ideal para que la consulta sea lo menos costosa.
Detectando los queries que tardan mucho tiempo
Todas las transacciones de Odoo deberían durar menos de 100 milisegundos. Si hay queries que duran más de 500 ms, deberíamos saber de ellos y al menos revisarlos para asegurarnos que no hay ninguna situación que tenga que ser corregida (por ejemplo falta de índices). Una forma rápida de saber esto, es modificando el archivo de configuración de postgresql (por lo general llamado postgresql.conf) y agregar la siguiente opción
log_min_duration_statement = 500
Que logueará en el archivo de log aquellas sentencias de SQL que duren más de medio segundo. Se verá en el archivo de log de la siguiente forma:

Aca se puede ver como una sentencia SELECT duró un segundo y medio. Si bien esta información es util, es una fotografía de lo que pasó en un momento y no indica si el query es realmente problemático o no (un query puede durar veinte segundos, pero si se lo ejecuta una vez por mes no es problema para nadie). Hay dos herramientas que permiten conocer si hay queries que presentan serios problemas de performance de manera persistente.
Como entender el plan de ejecución de un query
Cada vez que se ejecuta un índice el mismo pasa por cuatro etapas: parseo del query, reescritura, optimización y ejecución. La etapa de optimización es realizada por el optimizador de queries, el cual para ello utiliza las estadísticas sobre la dispersión de los datos de la base de datos. Es en ese momento cuando se decide si utilizar un índice, hacer sequential scan... etc. Lo que busca la base de datos es realizar el query de forma tal que sea lo menos costoso (a nivel recursos o tiempo).
Si tenemos un query problemático podemos conocer su plan de ejecución de la siguiente manera
EXPLAIN <query>
Por ejemplo; si queremos ver el plan de ejecución del query descripto en el punto anterior:
explain select min(res_partner.id) as id,count(res_partner.id) as city_count,res_partner.city as city from res_partner
where (res_partner.active = true) and (((("res_partner"."partner_share" IS NULL or "res_partner"."partner_share" = false )
OR ("res_partner"."company_id" in (1)))
OR "res_partner"."company_id" IS NULL )
AND (((("res_partner"."type" != 'private') OR "res_partner"."type" IS NULL) OR "res_partner"."type" IS NULL )
OR ("res_partner"."type" = 'private'))) group by city order by city;El cual dará el siguiente resultado
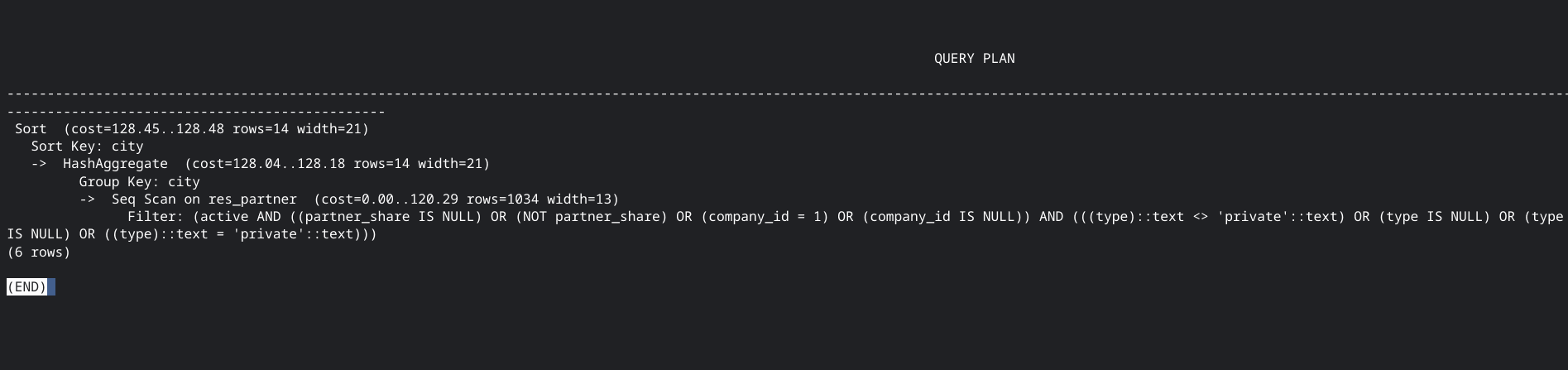
El cual se lee desde la parte interna derecha hacia afuera a la izquierda. En este ejemplo podemos ver como primero se aplica un sequential scan, luego se agrupa por una columna para al final ordenar por la misma columna. En la primer línea podemos conocer dos datos interesantes, la cantidad de filas que se estiman que se van a devolver (en este caso 14) y el costo del query; 128.45. Dicho costo es un costo interno de la base de datos. No representa tiempo ni IO ni nada. Es un costo interno, cuanto más alto, mas lento será el query.
Detectando la ausencia de índices
Una consulta que se puede utilizar para conocer a lo largo del tiempo cuales tablas están teniendo muchos sequential scans es la siguiente:
select schemaname,relname,seq_scan,seq_tup_read,idx_scan,seq_tup_read / seq_scan from pg_stat_user_tables
where seq_scan > 0 order by seq_tup_read desc;

Esta consulta muestra información como: cantidad de sequential scans que tuvo una tabla, cantidad de registros leidos en cada sequentail scan, cantidad de veces que se leyó con un índice la tabla, cantidad de registros leidos en cada sequential scan. En este ejemplo podemos observar la tercer línea para la tabla t_test; la cual no tuvo ningún uso del índice, tuvo 8 sequential scans y en cada uno leyó 1,250,000 registros (una situación muy común en Odoo). Esa tabla es candidata para la creación de un índice.
Los índices que crea Odoo
En el 99% de los casos los índices de una tabla en Odoo son creados al momento de instalarse un módulo. Por defecto Odoo crea un índice sobre la columna ID (para mantener la integridad referencial de la clave primaria). Y el resto de los índices son creados por el desarrollador del módulo mientras se desarrolla el módulo (momento en el cual uno nunca piensa en la performance de las consultas). Es por eso que podemos ver situaciones como la tabla sale_order_line, donde vemos que existen los siguientes índices:
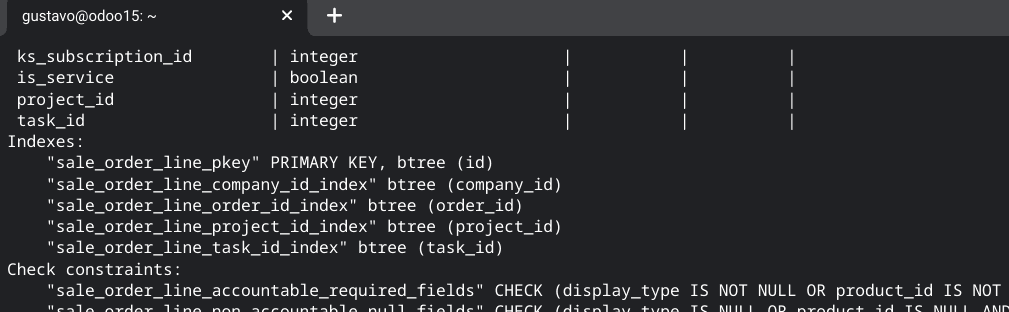
Como podemos ver tenemos índices para la clave primaria, para la compañía (en un entorno que no resulta ser multicompañía), el pedido de ventas (lo que tiene mucho sentido), el proyecto y la tarea (estos últimos creado por el módulo project). Es una instalación de e-commerce. Por que Odoo instaló los índices de proyectos en un sistema que va a manejar miles de órdenes y solo dos o tres proyectos? Es un misterio para mi. Mi punto es, a medida que vaya usando el sistema, analice que índices se encuentran presente y si le son de utilidad. Por ejemplo, en este ejemplo que es de e-commerce yo borraría los índices relacionados con proyectos y crearía uno para productos.
Como se crean índices
Los índices se crean con las herramientas de mantenimiento de base de datos. Para ello se utiliza el comando CREATE INDEX. Por ejemplo
create index idx_partner_city on res_partner(city)
Creará un índice binario sobre la columna city de la tabla res_partner. En el siguiente screenshot podemos ver el efecto de realizar un query sin el índice y con el índice
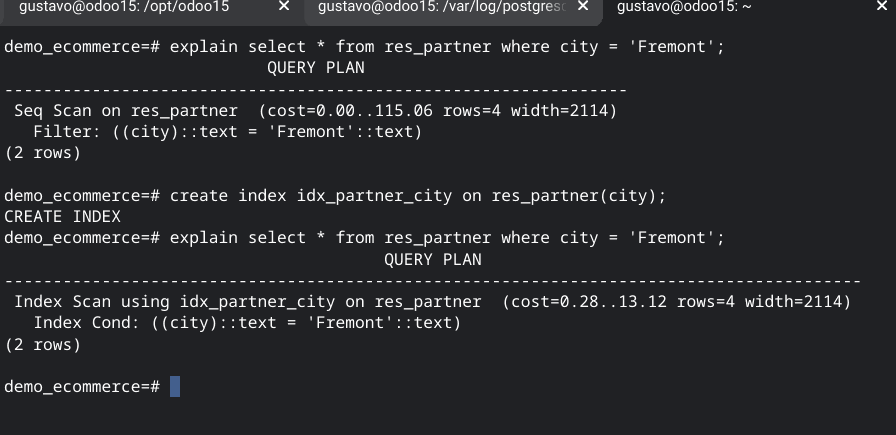
Se puede ver el primer query (sin el índice) tiene un costo de 115. Una vez ejecutado el índice, el costo se reduce a 0.28.
Extensión pg_stat_statements
Lo que explicamos hasta ahora tiene una gran limitación, son una foto y no te indican si un query se está realizando con frecuencia o no. Lo que es importante es; optimizar aquellas consultas de alto costo que se realicen con frecuencia. Como podemos saber cuando un query se ejecuta muchas veces? Podríamos conocerlo con la extensión pg_stat_statements del paquete contrib (que ya se encuentra incluido con PostgreSQL).
Se instala así:
create extension pg_stat_statements;
Y luego se tiene que habilitar la extensión en el archivo de configuración de PostgreSQL
shared_preload_libraries = 'pg_stat_statements' # (change requires restart)
A continuación se debe reiniciar PostgreSQL. Esta extensión crea una tabla muy util, pg_stat_statements. La que contiene por cada query la cantidad de veces que se ejecutó, el tiempo total, tiempo mínimo y máximo, el tiempo promedio y el desvío, la cantidad de registros y estadísticas de IO. Realmente muy util. Por ejemplo, supongamos que tenemos una tabla llamada t_test de la cual queremos ver que consultas se estan ejecutando, solo tenemos que hacer:
select * from pg_stat_statements where query like '%t_test%';
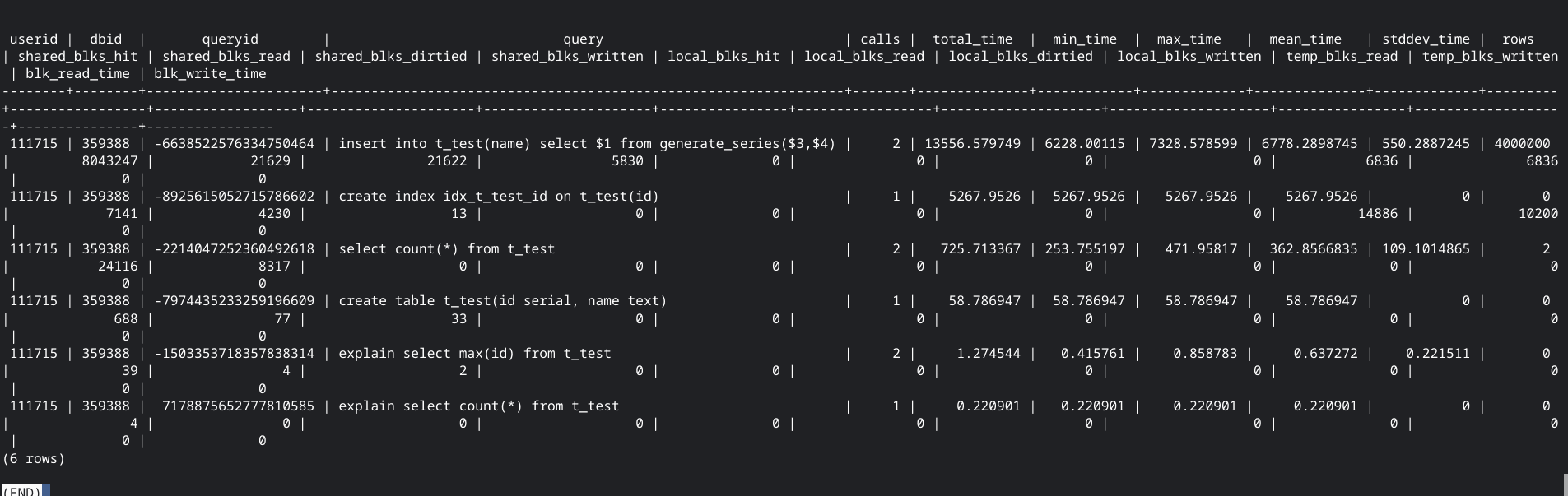
pg_stat_statements es una extensión que debe estar instalada en cada base de datos que uno estima va a crecer en tamaño y usuarios. Es una extensión "liviana"; es decir practicamente no penaliza la performance del sistema por su uso (la verdad la base de datos ni se entera).
Reseteando las estadísticas
Muchas veces necesitamos borrar las estadísticas de la base de datos para arrancar de nuevo (por ejemplo para conocer si un cambio que hicimos surtió efecto). En ese caso debemos utilizar el comando pg_stat_reset de la siguiente manera:
select pg_stat_reset();
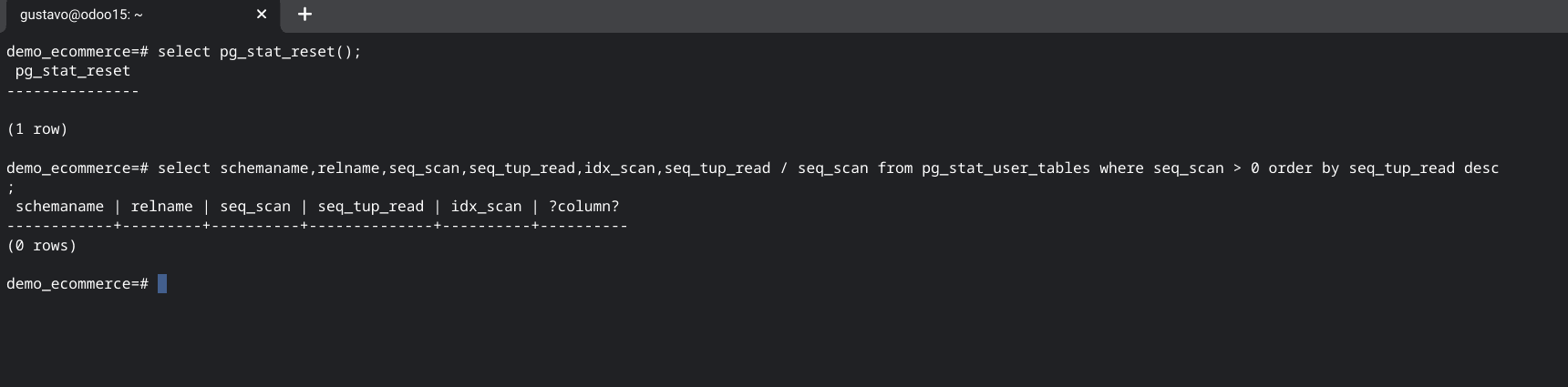
Como pueden ver en el ejemplo, despues de ejecutarlo las estadísticas de la cantidad de sequential scans por tabla están vacías. Para resetear las estadísticas de la extensión pg_stat_statements debemos ejecutar pg_stat_statements_reset
select pg_stat_statements_reset();
Vacuum
Vacuum es un comando que reclama el espacio no utilizado por una base de datos. Las bases de datos de PostgreSQL tenden a crecer a lo largo del tiempo, debido a que los registros actualizados o borrados no son eliminados del filesystem (son marcados logicamente como borrados, por ejemplo). VACUUM elimina físicamente esos registros no utilizados. También realiza otras tareas; como por ejemplo actualizar las estadísticas de la base de datos (para que el optimizador funcione de forma apropiada) y recrear los índices.
El siguiente query nos indica cuando podemos ejecutar el VACUUM;
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_autovacuum FROM pg_stat_all_tables ORDER BY n_dead_tup / (n_live_tup * current_setting('autovacuum_vacuum_scale_factor')::float8 + current_setting('autovacuum_vacuum_threshold')::float8) DESC LIMIT 10;
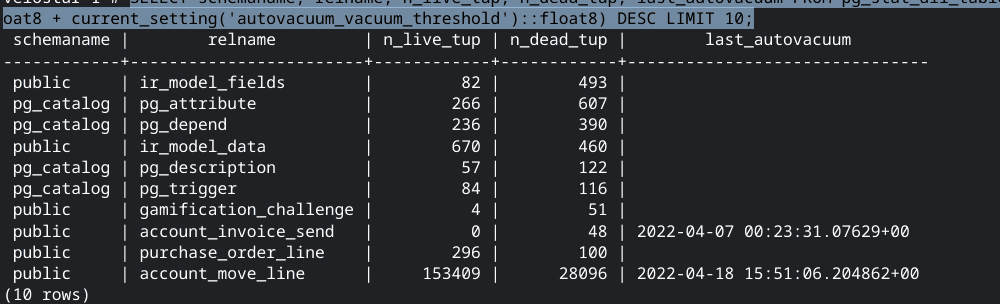
Como podemos ver la tabla account_move_line tiene unos 28,096 registros muertos y unos 153,409 registros vivos. Un 15% de la tabla. Y si chequeamos el tamaño de dicha tabla con el comando pg_total_relation_size
SELECT pg_size_pretty( pg_total_relation_size('account_move_line') );
Podemos ver que la tabla ocupa unos 216Mb. Ahora vamos a ejecutar el VACUUM para la base de datos:
VACUUM FULL;

Como podemos ver, el tamaño de la tabla pasó de 216 Mb a 94 Mb. Una reducción considerable.
La función VACUUM tiene muchas opciones, como por ejemplo ejecutarse solo para una tabla o ejecutarla y actualizar las estadísticas de la base de datos. En un principio recomiendo en horarios en los que no trabajan los usuarios, realizar un VACUUM FULL. Este comando solo requiere espacio en disco suficiente y que no se esté ejecutando Odoo (ya que requiere un lock exclusivo de cada tabla de la base de datos). Pero es el comando que compacta las tablas, recrea los índices y actualiza las estadísticas de la base de datos. Es muy completo. Tenga en cuenta que puede llegar a tener una larga duración.
PostgreSQL cuenta con la opción de que se ejecute el VACUUM en forma automática, no lo cubriremos en este post. Lo importante es comprender que hace el VACUUM y cuando utilizarlo.
Acerca de:
Gustavo Orrillo
Apasionado de la programación, implementa Odoo para distintos tipos de negocios desde el año 2010. En Moldeo Interactive es Socio fundador y Programador; además de escribir en el Blog sobre distintos temas relacionados a los desarrollos que realiza.
Cambiando el tipo de cambio en los pagos en Odoo
Bien... esto funciona en Odoo 15, no ya en Odoo 14. Ya verán porque. En Odoo 15 se permite el ingreso de los pagos; los cuales generan en forma auto...
Seguir leyendoProcesando ingresos de mercadería
Por lo general, los ingresos de mercadería son creados automáticamente desde una orden de compra. Tambien se los puede crear manualmente. Solo tiene...
Seguir leyendoAgregando campos para consultar stocks
Los stocks en Odoo estan representados en el modelo stock.quant. El cual tiene muchos campos por los cuales consultar, pero muchas veces eso no es s...
Seguir leyendo