Cargando el padrón de AFIP y ARBA
En este post ya escribí sobre el uso del método load para la inserción y actualización de miles de registros. En este post vamos a hablar sobre la importación del padrón de ARBA o de AFIP, los cuales tienen millones de registros. El padrón de ARBA de Percepciones de IIBB tiene casi cuatro millones de registros, y su carga en Odoo mediante xmlrpc lleva horas. Es por eso que quiero probar otra alternativa, en este caso el método load.
El formato de algunas líneas del archivo es el siguiente:
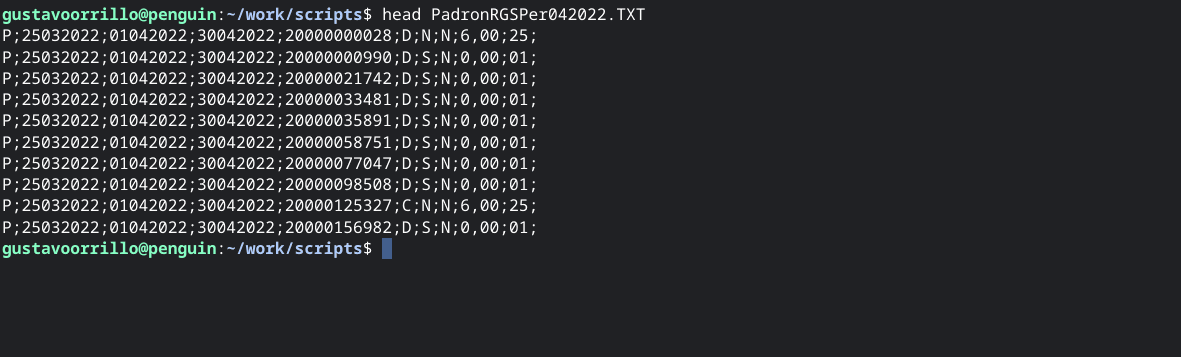
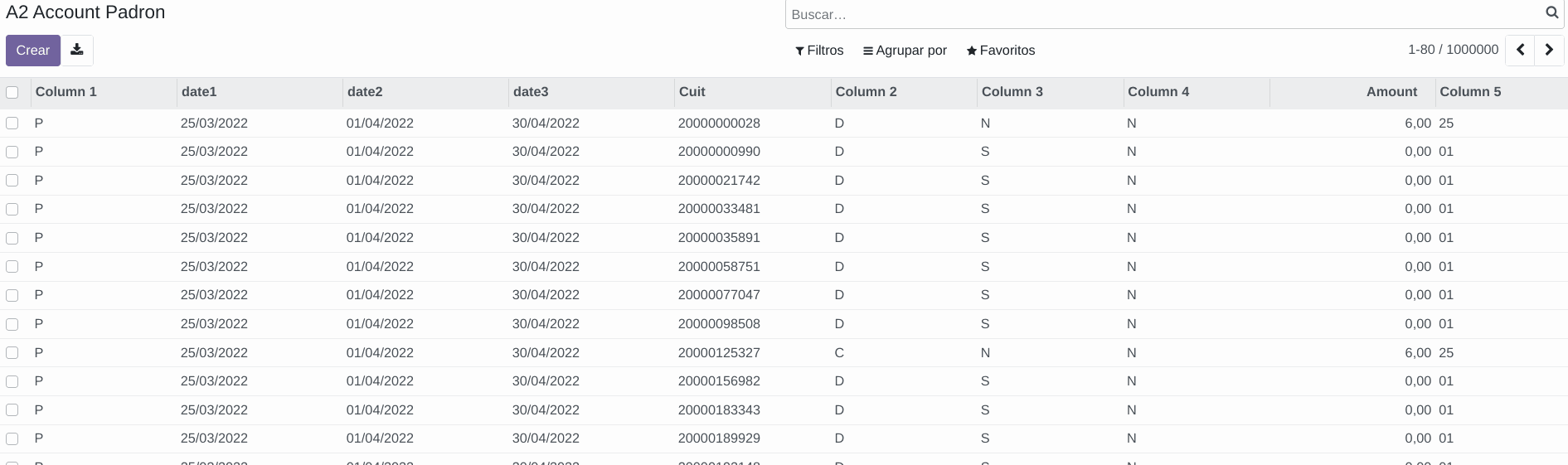
Donde tenemos un par de columnas con la fecha desde y hasta, tenemos una columna con el CUIT y otra columna con el monto a percibir. Este padrón será persistido en un modelo de prueba que se llama a2.account.padron y con la siguiente estructura:
column1 = fields.Char('Column 1')
date1 = fields.Date('date1')
date2 = fields.Date('date2')
date3 = fields.Date('date3')
cuit = fields.Char('Cuit')
column2 = fields.Char('Column 2')
column3 = fields.Char('Column 3')
column4 = fields.Char('Column 4')
amount = fields.Float('Amount')
column5 = fields.Char('Column 5')Como verán, las columnas son de prueba. Al fin y al cabo estoy haciendo esto para probar los tiempos de carga del padrón. Para cargar el padrón, desarrollamos el siguiente método:
@api.model
def load_a2_account_padron(self):
csv_file = open('/tmp/PadronRGSPer042022.TXT','rt')
csv_reader = csv.reader(csv_file, delimiter=';')
line_count = 0
fields = ['id','column1','date1','date2','date3','cuit','column2','column3','column4','amount','column5']
data_lines = []
print(str(datetime.now()))
for row in csv_reader:
line_count = line_count + 1
date1 = date(year=int(row[1][4:8]),month=int(row[1][2:4]),day=int(row[1][:2]))
date2 = date(year=int(row[2][4:8]),month=int(row[2][2:4]),day=int(row[2][:2]))
date3 = date(year=int(row[3][4:8]),month=int(row[3][2:4]),day=int(row[3][:2]))
data_line = ['account.padron.' + str(line_count), row[0],str(date1),str(date2),str(date3),row[4],row[5],row[6],row[7],float(row[8].replace(',','.')),row[9]]
data_lines.append(data_line)
if line_count % 1000 == 0:
res = self.env['a2.account.padron'].load(fields,data_lines)
data_lines = []
print(line_count)
print(str(datetime.now()))
csv_file.close()
Como el método load espera una lista con los valores a actualizar, en este caso el método load se invoca cada 1,000 registros leídos. Si intentamos invocar el método load pasándole como parámetro una lista de datos de millones de registros, se queda sin memoria Odoo.
La performance del método es bastante buena, ya que procesa 1,000,000 de registros cada 13 o 14 minutos. Lo que hace que se actualice un padrón de casi 4,000,000 de registros en alrededor de 50 minutos. Hay que prestar atención al tuning de los checkpoints en la base de datos, ya que los mismos pueden acelerar o retrasar el proceso de carga. Pienso que un tiempo de carga de menos de una hora para actualizar el padrón es aceptable, ya que si lo hacemos mediante xmlrpc se ejecuta mínimo en unas cuatro horas.
Acerca de:
Gustavo Orrillo
Passionate about programming, he has implemented Odoo for different types of businesses since 2010. In Moldeo Interactive he is a founding Partner and Programmer; In addition to writing on the Blog about different topics related to the developments he makes.